The global market of sports analytics is the shifting curve, and cricket is at the epicenter of this data revolution with the emergence of free cricket APIs. Developers and data scientists who want to create their own live score trackers, fantasy sports apps, or statistical analysis dashboards need a consistent, reliable supply of structured data. But the abovementioned API providers are charging thousands of dollars for commercial API access, which is bad news for the people who run a small community sports website or app.
Paying for it is also completely impractical, and that’s the financial incentive behind why engineering frameworks lean so heavily on free cricket APIs to democratize access to data, the ability for anyone to track player match-ups, ball-by-ball trajectories, and historical archives without breaking the bank. With the design of new software systems becoming more modular, making some of your infrastructure open source, like the free cricket APIs changes the operating game completely. Developers and data scientists who want to create their own live score trackers, https://cricproz.com/best-fantasy-cricket-apps-2026/ to earn money or statistical analysis dashboards need a consistent, reliable supply of structured data.
By adding community-based free cricket APIs, you can definitely avoid some or all of the headaches involved in writing custom web scrapers that break every time an official tournament host decides to re-format their website. Instead of dealing with the hair-pulling frustration of raw HTML or suffering the innumerable wrap errors of regex parsing overwhelming your system, these free and paid cricket APIs data endpoints deliver clean JSON or CSV payloads straight to your backend systems. Instead of fighting raw HTML or broken regex parsing, these cricket APIs deliver clean JSON or CSV payloads directly to your backend. And if you ever need a break from coding to enjoy the game physically, you can also learn https://cricproz.com/how-to-build-a-backyard-cricket-pitch/ for real-world practice.
Table of Contents
1. CRICSHEET DATA FORMAT PIPELINE
Clipsheet is the premier standard in free cricket APIs for ball-by-ball deep analytical data without any commercial payload restrictions for developers. Rather than exposing active REST endpoints like traditional web services, Clipsheet adopts an entirely open-source model by organizing raw match records into clean, version-controlled YAML, JSON, and CSV files.
This design philosophy exempts you from concerns about running into third-party API rate limits or being at their mercy for uptime on high-traffic events like World Cup finals, since the structured data dumps are available for download and can be stored within your application’s file architecture or loaded directly into a local PostgreSQL or MongoDB instance. So, Clipsheet’s internal data structure is crazy detailed. Instead, you download the structured data dumps directly from the official open-source Cricsheet platform into your application’s file architecture.
Every bowler name, batting metrics, exact delivery runs, extras split by wides or no-balls, wickets, fielder involvements, and even advanced match details like stadium metadata and referee officials are recorded on every event on the free cricket APIs field. Whether you are training a machine learning model to predict the run rate in the second innings or building an elaborate statistical dashboard of historical bowling strategies, this open-source design beats out most free cricket APIs, as you get raw data logs without being filtered by any pre-built calculations so you can run your own algorithms seamlessly.
2. CRICKET DATA NODE.JS WRAPPER ENGINE

For those wholly focused on asynchronous JavaScript stacks, the free cricket APIs community has also cooked up dedicated Node.js packages that wrap public endpoints as native Promise-based functions. These wrappers use open data indexes to fetch real-time structure endpoints and match timetable and player profile up-to-date arrays. Using an event-driven architecture, these frameworks enable Node.js backend developers to create asynchronous data loops and have an endless refreshing of user interfaces without needing users to refresh the pages manually.
The subforum payloads are the following: a forthcoming fixture list, live matchboards exercised currently with live updates, and all-round cricket international players’ career profiles. They follow the response structures, which are natively lightweight JSON objects that can be served directly to a frontend client through an Express route module or emitted to client views via Socket.io for a rich, low-latency live experience reminiscent of premium free cricket APIs. The free cricket APIs community has also cooked up dedicated Node.js packages that wrap public endpoints as asynchronous Promise-based functions.
3. PYTHON CRICKET-CLI UTILITY ENGINE
A host of terminal-centric developer modules exist in open-source land, and Python CLI packages continue to be the go-to option for backend microservice setup. These command-line utilities are also open data routers that scrape, clean, compile, and structure lightweight streams on the free cricket APIs on the fly. Based on parsing libraries from standard libraries (e.g., Beautiful Soup) or protocol data formats like JSON or XML or custom protocol-based (asynchronous) data implementations, these modules aggregate data from raw web data and produce structured, reusable components.
The great advantage in using a CLI micro-engine is that it eliminates the need for free cricket APIs and big database instances for easier applications. It processes terminal configurations, connects to public networks, and produces clean streams to terminal stout or to flat JSON configurations. If you want to create automation bots, Discord plugins, or cron job scripts that just sit silently in your server’s background and generate automated cricket reports, this approach is a great alternative for self-hosted, free cricket APIs. Based on parsing modules from standard utilities like the Beautiful Soup library or protocol data formats.
4. GO-CRICKET DATASTREAM CONCURRENT REPOSITORY
Developing scalable sports web ecosystems where your free cricket APIs are managing hundreds of thousands of concurrent hits per minute, language efficiency is your biggest engineering bottleneck. Go (Golang)-based repositories for cricket data stream ingestions are extremely fast in terms of parallel execution. These open engines handle binary protocols or fast JSON channels with a unique use of lightweight Go routines that split data queries across multiple CPUs in parallel.
Parameters are mapped into hardcore statically typed structures (structs) in the underlying data matrix. This type of typing scheme means your app will never face abrupt execution disruption because of null values or data type modifications that aren’t expected within the data array. The structures cleanly separate team information, player rankings, ball speeds, and cumulative run rates into memory-efficient matrices, enabling snappy performance even in real-time applications that are very popular free cricket APIs.
5. R-SPORTS DATA SCIENCE CRICKET FRAMEWORK
For those who analyze data (such as academics or sports journalists), what data collection amounts to is doing statistical deep-dives and creating interactive data visualizations. The free Cricket API R language ecosystem has a number of domain-specific open-source packages for interacting with historical databases and cricket repos. These scripts transform raw sports data into clean data frames, tailored to particular statistical packages such as ggplot2 or dplyr. These scripts transform raw sports data into clean data frames, tailored to particular statistical packages such as ggplot2 data visualization or dplyr.
Instead of presenting data in active arrays in real-time, information is organized in high-dimensional data matrices in these frameworks. They also deliver clean data functions to fetch filtered and multilayered datasets of particular sports eras, particular international player-tier groups, or even full stadium weather records. So, you can analyze complex statistical parameters without having to shell out for the premium sports feeds—what better way to serve the analytical needs of free cricket APIs? They also deliver clean data functions to fetch filtered datasets of specific sports eras or full stadium weather records, helping you analyze https://cricproz.com/weather-impact-pitch-fantasy-cricket/ without paying for premium feeds.
6. DATABASE INDEXING & CACHING IMPROVEMENT
Open-source systems enable building platforms at the cost of high-speed appliance layer 8; however, when you roll out any open-source system-based platform, it is very important to consider a well-designed database caching layer to keep high speeds of the application. If your system is calling out to remote, third-party, public servers every time a visitor refreshes your app, that’s going to slow down your performance, and those free cricket APIs may be getting your IP blacklisted for abusing their resources. Using a local caching layer, such as Redis or Memcached, as a go-between is crucial in shielding your server resources from public data infrastructure.
For live scores provided through free cricket APIs with active TTL on the scores, a 5-10 second cache TTL is suggested. This sweet spot keeps your data fresh for sports fans while reducing outbound network requests up to 95%. For historical data sets or player biography profiles, increase the TTL to 24 hours, or store the elements in local storage pools. This design ensures your sports site loads quickly, holds up well under peak traffic surges, and performs impeccably.
7. DOCKERIZED MICROSERVICE INGESTION PIPELINES
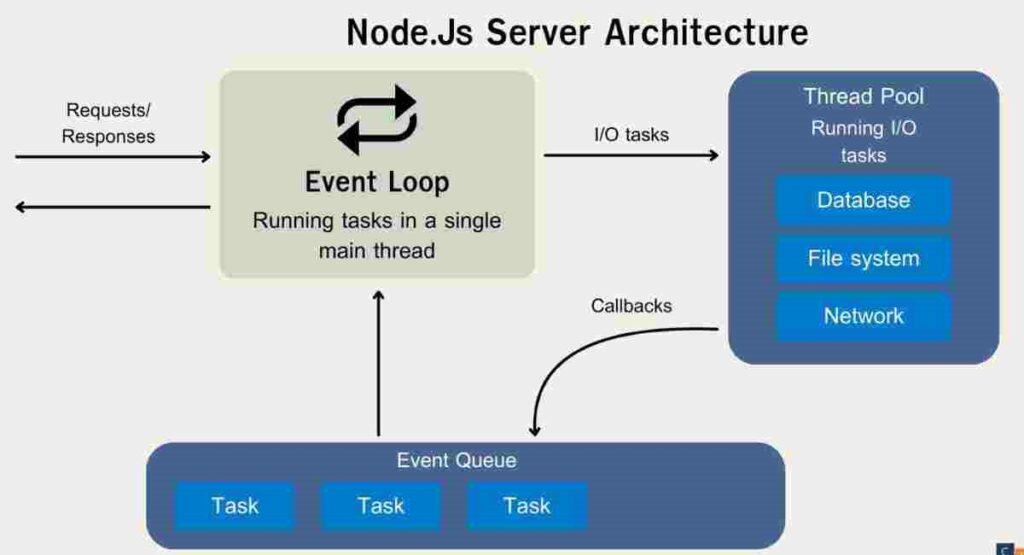
When dealing with a modular infrastructure and open-source cricket APIs, keeping the environment consistent across the different languages (Python, Go, and Node.js) can be a real pain in the ass to configure. That’s where containerized orchestration with Docker and Kubernetes fits in as the missing piece for modern data architectures.
Rather than running a bunch of bare scripts on your backend engine, developers bundle up their Python scrapers, Go data streams, and Node.js wrappers as stand-alone, lightweight microservices. That’s where containerized orchestration with Docker and Kubernetes fits in as the missing piece for modern data architectures.
Key Architectural Advantage: This methodology provides for absolute environmental uniformity. Because your local environment is exactly the same as your production server, you are less likely to experience abrupt runtime errors from mismatched package dependencies or OS discrepancies.
Plus, when you standardize your environment by docking your ecosystem, you can containerize your local Redis or Memcached caching layers in addition to your data routers. With a single orchestration file (docker-compose), you can launch your entire setup in isolation with your ingestion script, a live memory-cache store, and your frontend API router using a single command.
In case of a sudden traffic spike during a high-profile tournament, horizontal scaling allows you to spin up more identical clones for handling and processing loads so your entire infrastructure remains running and available and your core application infrastructure is completely protected.
CONCLUSION:
Now, building a professional sports portal/high-end interactive app does not have to cost an arm and a leg with sports data syndication contracts. By electing to leverage the strategically optimized free cricket APIs, developers and site owners can bypass giant commercial paywalls and gain access to rich, structured data sets across almost any production environment.
Whether your tech stack ultimately thrives or fails is wholly up to how well you select the tool that fits the architecture of your requirements: Clipsheet for raw, unparsed historical data; Node.js or Go for lightweight, highly concurrent real-time application pipelines; and R frameworks for statistical data science modeling. When combined with powerful local caching layers such as Redis and well-designed container-based systems, these public hubs allow your website to load insanely fast, be rock solid during massive World Cup traffic spikes, and grow organically for years to come with no cost at all.
Frequently Asked Questions (FAQs)
Q1. What are the best free cricket APIs for fantasy sports app development?
Answer: This will depend on what your tech stack is, but Clipsheet is the undisputed gold standard when it comes to rich historical data and complex player-based math modeling. There are also a few real-time (i.e., live) application Node.js wrappers and Go repositories currently observing the live payloads, which handle it for you and convert it into nice JSON structures.
Q2. Do free public cricket APIs give live updates of matches ball by ball?
Answer: Some are but have restrictions. Open-source wrappers in Node or Golang are excellent for streaming live scoreboards by polling open data indexes. However, some solutions like Clipsheet are structurally devised for post-match archival dumps, and most of their clean DB files are usually published a few hours after the match is wrapped up.
Q3. How do I protect my server IP from getting blacklisted while using free cricket APIs?
Answer: You need to enforce a heavy localized caching layer such as Redis or Memcached as a middleman gatekeeper. Set a cache TTL for the changing data, such as live score lines, of 5–10 seconds. This simple trick keeps data fresh for sports aficionados, while simultaneously blocking up to 95 percent of those unnecessary outbound server queries.
Q4. Can we develop a mobile app from the Python CLI cricket app engine?
Answer: Python CLI tools are great for terminal automation, cron jobs, or Discord bots, but they’re not really suitable for direct backup of mobile apps. Instead, think of a CLI tool as a quiet microservice that scrapes and dumps structured text into a central database, and then use something like an Express or Fast API framework to make that data available to your mobile clients.
Q5. Why should I prefer free cricket APIs over building a custom web scraper?
Answer: The visual layouts of the official cricket tournament sites and the HTML markup code are changing regularly. Your custom scraper will break every time they change just one line of frontend code. Community APIs handle these updates on their side, so you get a seamless, reliable stream of structured JSON or CSV data.
Q6. Is it challenging to deal with the sudden onslaught of heavy traffic with free cricket APIs?
Answer: It can be poor if. To serve hundreds of thousands of simultaneous hits during a big tournament, opt for a high-performance backend language such as Go (Golang). Go uses lightweight routines to parse data in parallel on multiple CPU cores.
Q7. Are free cricket APIs inclusive of domestic leagues such as the IPL, PSL, and Big Bash?
Answer: Certainly, major community-maintained repositories offer extremely comprehensive coverage of all formats of cricket, including Test, One Day International (ODI), and T20 International, as well as major domestic T20 franchised leagues across the world.
Q8. In what data formats are open-source cricket databases available?
Answer: They use very light data configurations most friendly to developers. There are raw JSON or YAML files for structured player arrays and nested objects and clean CSV files for tabular sheets, which can be used immediately in spreadsheet apps.
Q9. How do data scientists use free cricket APIs for sports prediction?
Answer: Data scientists use their tools of choice, such as R and Python, to download nested datasets from public repositories. These tools convert historical data into cumbersome data matrices, enabling scientists to line plot pitch condition behavior and run machine learning models—all without purchasing from the premium sports feeds. If you want to convert these analytical skills into a full-time profession, check out our guide on https://cricproz.com/cricket-data-analytics-jobs-2026/ available today.
Q10. Why should I use Docker for a cricket database ingestion setup?
Answer: When you Dockerize your application, your scrapers, Go streams, Node.js routers, and Redis caching layers are separated into distinct, lightweight microservice containers. It provides for perfect environmental parity between your local machine and your deployment servers and safeguards against crashing due to mismatched library dependencies or OS changes. Data scientists use tools of choice like R and Python to download nested datasets from public repositories. To explore this further, you can learn from https://cricproz.com/ai-chatgpt-dream11-prediction-2026/ to build your machine learning models without purchasing premium feeds.